Evaluating GPT-4o-Mini for Handwritten Text Recognition
In my last blog post, I have qualitatively evaluated gpt-4o's handwritten text recognition on my journal notes. As every software product needs some form of evaluation, I now quantify here the performance of the recently released gpt-4o-mini in transcribing my handwritten journal notes.
For any evals, you need the ground-truth labels aside from the model's output. I used my phone's speech-to-text feature to transcribe 100 entries at a rate of 6-8 entries per hour. I had to put in lots of hours of manual labor - reading the entries out loud and correcting the transcribed texts. It took me two full days to generate the 100 ground-truth transcriptions.
Moreover, I chose to transcribe journal entries from different time frames: January, March, and June. In this way, I’ll have some insights on how my journal entries and handwriting progressed over time.
There are five key insights I gained from building my evals for a vision-language model (VLM):
1. I’ve been writing more as months went by.#
The lengths of my journal entries have increased over time as seen in the line plots of the number of characters and words over time below. Their variances have also increased, implying how they became more fluctuating in length over time.
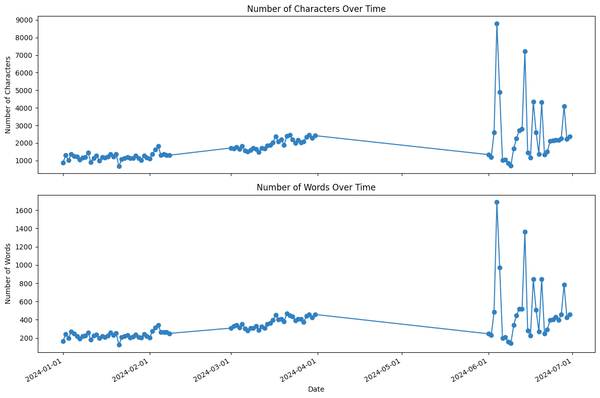
I’ve been writing 353 words every day on the average, with a standard deviation of 224 words. The shortest entry was on January 21, 2024 with 124 words, and the longest entry was last June 4, 2024 with 1,691 words. Coincidentally, this was the day of my thesis defense (and family celebration!), so I really had a lot to document that day.
Moreover, note that the two line plots are similar as the number of characters and words are highly correlated to one another.
2. A Closer Look on CER and WER Evals#
For my task, I chose two evaluation metrics common to the neighboring fields of Optical Character Recognition (OCR) and Handwritten Text Recognition (HTR). The first metric is the Character Error Rate (CER) which gives insight into the accuracy of character-level recognition in the HTR process. It is mathematically defined as
where
For the second metric, the Word Error Rate (WER) measures the accuracy of word recognition. It is mathematically defined as
I chose CER and WER metrics as they are sensitive to the order of words in the text, thus incorporating the extent of the insertion and erasure problems I have previously identified for the HTR task.
I used the dinglehopper library to calculate the CER and WER metrics. For WER, dinglehopper uses the Unicode method to segment words. While it is sensitive to capitalization, this word segmentation algorithm ignores punctuation marks at the start and end of a word. This is a bit of a downside, as WER cannot incorporate the extent of the punctuation mark removal problem.
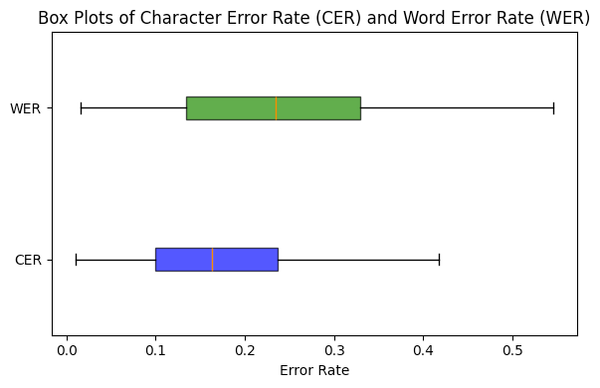
As seen in the box plots above, gpt-4o-mini's resulting CER and WER have means of 17.5% and 24.% and standard deviations of 9.3% and 12.6%, respectively. These error rates are pretty high: on the average, one in every four words are transcribed incorrectly! I speculate that these could be improved by prompt engineering or model fine-tuning.
3. The error rates of gpt-4o-mini were increasing over time.#
As gpt-4o-mini processed my journal entries for the months of January, March, and June, we could see in the box plots below how the error rates have increased over time. Specifically, both CER and WER more than doubled within six months, with WER rising from 15% in January to 32% in June. As these entries were batch processed by the model, the error rates are not only due to the gpt-4o-mini's performance, but also due to the quality of my handwriting. I have been writing more over time, so it's natural that my handwriting got messier and the spaces between text lines have become narrower. I view variations in handwriting legibility as a feature, not a bug, of the HTR system. The model should be able to handle my different handwriting styles, whether it's cursive or print, well-formed or hurried.
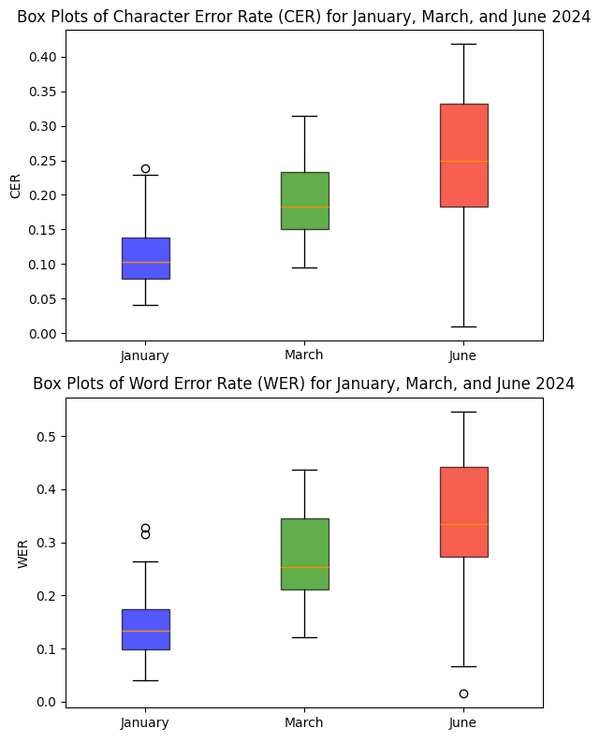
Moreover, note how the standard deviations of the WER metric have been increasing as well over the months: 7.0% in January to 8.2% in March to 15.3% in June. While the error rates were pretty low and somehow consistent in January, they were fluctuating a lot more in June.
4. Better data quality translates to better model results.#
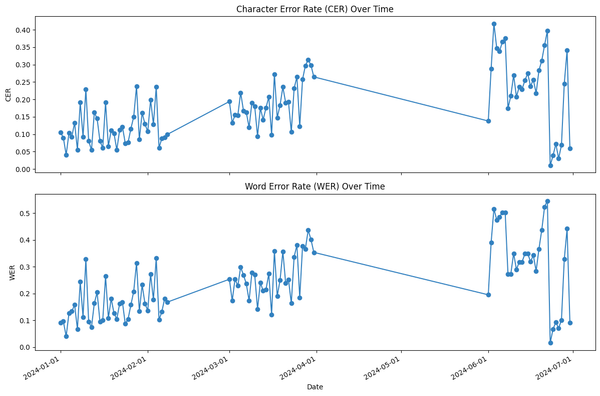
If you observe the line plots of the error rates over time as visualized above, there is a big drop in both CER and WER in June. You can see the change before and after June 23, when I deliberately started to fix my handwriting for LLM ingestion. Below are snapshots of the first few lines of my June 22 and June 23 entries. Take a look at the glaring contrast of my handwriting legibility in just a one-day difference.


In fact, while my June 22nd entry had the highest WER of 54.6% across all 100 entries, my June 23rd entry had the lowest WER of 1.5%. What a massive drop of 53.1% in the error rate! This underscores the importance of having high-quality raw data. My clearer handwriting resulted to better output from gpt-4o-mini.
5. There are other factors contributing to error rates aside from text length.#
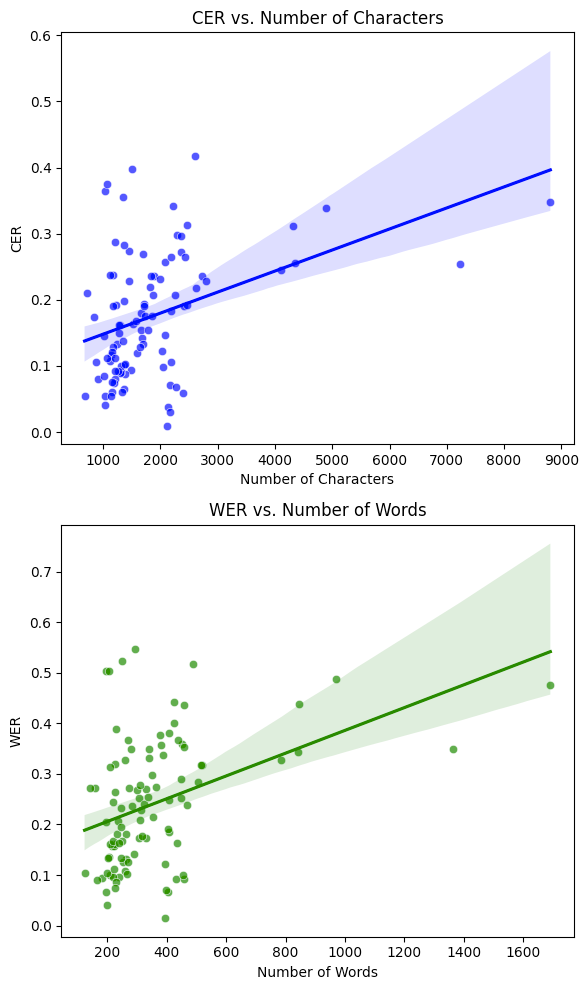
I generated the following scatter plots of CER vs. Number of Characters and WER vs. Number of Words. Both of these relationships have a correlation of 0.40. Such a moderately positive correlation suggests that while there is a positive, linear relationship between the length of the text and the error rates, it's not strong enough to be highly predictive. There are likely other variables affecting the error rates that are not captured by text length alone. I speculate that these include my handwriting quality and style (as I have noted earlier), consistency of my handwriting, and of course the choice of VLM model. I've also changed the brand of the pen I use for journaling in June, so the difference in line thickness and ink quality may have contributed to the fluctuating error rate as well. Lastly, since our multimodal model takes images as inputs, the quality of how the pictures are taken and the lighting conditions might also affect the model's error rates.
Conclusion#
For the task of recognizing the handwritten text from my 100 journal entries, gpt-4o-mini produced an average word error rate of 24%, and the individual error rates can go as low as 1% and as high as 50%. These error rates are pretty high and unstable: imagine you spot an incorrect word for every four words transcribed. Moreover, while better data quality translates to lower error rates, my model should be able to handle my varying handwriting style and legibility. Beyond the factors I can control (such as my handwriting, the pen I use, and image quality), my analysis posits the need for a better model. Now that I've built the evaluation pipeline for my HTR task, I'm excited to try out other models and explore using other techniques, such as prompt engineering and fine-tuning, in the quest to improve model performance.