The Prompt-tastic Art for Better Handwritten Text Recognition
One of the key findings from my last blog post is the potential of prompt engineering to improve GPT-4o-mini's performance on the Handwritten Text Recognition (HTR) task of transcribing my handwritten journal notes. After setting up Character Error Rate (CER) and Word Error Rate (WER) as our evaluation metrics, we are now ready to experiment on prompting tactics to squeeze more value out of vision-language models (VLMs).
Prompt engineering is a science as much as it's an art. In this blog post, we'll follow the following directed acyclic graph for our prompt iterations:
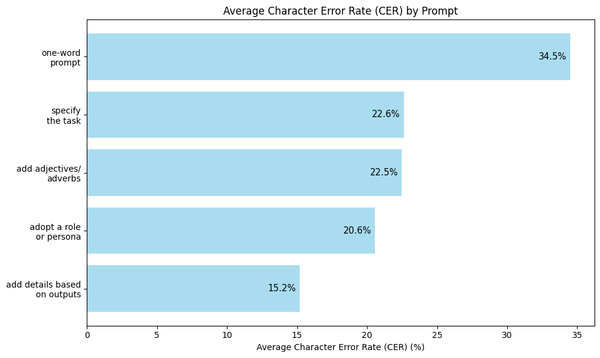
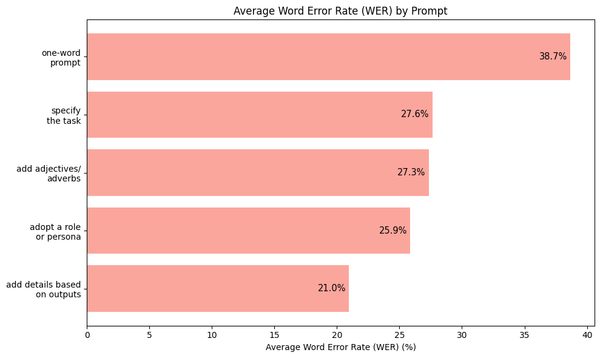
To provide you a snapshot, here are the bar plots of the average CER and WER as I cumulatively use each prompting tactic. Keep these charts in mind as we go through the details of each prompt.
Prompt 1: Always start with the simplest prompt#
As with any iterative experimentation, I started with the simplest system prompt, and increase the level of its complexity based on gpt-4o-mini's outputs. Specifically, I started with just one word:
prompt = "Transcribe"Using this prompt, the average CER over 100 journal entries is 34.5% and the average WER is 38.7%. This is pretty bad - imagine getting one word wrong for every three words transcribed by the model! But this is a good benchmark nonetheless: we can only improve from here as we have used the simplest prompt imaginable for our task.
Prompt 2: Specify the task#
We can make the prompt more specific by providing context to what our model's task is. By doing so, we steer the model to use this context in performing the task.
For my prompt, I specified that the text that needs to be transcribed is handwritten:
prompt = """Transcribe the handwritten text from
this image."""As can be seen in the two bar plots above, the average CER and WER decreased by large margins of 11.9% and 11.1%. With this simple and straightforward prompt, gpt-4o-mini was able to perform better - now with just one wrong word on the average for every four words it transcribed.
Prompt 3: Add adjectives/adverbs#
Another helpful prompting technique is adding adjectives and adverbs to describe how we want the model to do a task or how its output should look like.
For my HTR task, I was curious how adding the adverb "accurately" in the prompt will impact the model's performance.
prompt = """Transcribe the handwritten text from
this image accurately."""This third iteration of our prompt resulted to a marginal decline of 0.1% and 0.3% in average CER and WER, respectively. As expected, the addition of this single word had a small impact on gpt-4o-mini's performance, but an improvement nonetheless.
Prompt 4: Prompt the model to adopt a role or persona#
As mentioned in OpenAI's Prompt Engineering Guide, a useful prompt engineering tactic is to ask the model to adopt a role or persona. This guides the model to generate its response according to one's preferred style, verbosity, and tone.
In my case, I added another sentence at the start of the prompt to set my expectations on gpt-4o-mini's role. Since I have described already in the persona statement that the text to be transcribed is handwritten, I removed the redundant adjective in the succeeding task statement:
prompt = """You are the world's greatest transcriber
of handwritten notes. Transcribe the text from this
image accurately."""With this prompt, the average CER and WER dropped to 20.6% and 25.9%, respectively. These are significant improvements from our previous prompts.
Prompt 5: Add details in the prompt based on model's outputs#
For people working on AI, data is our world's currency. So it's imperative to look at your data. This involves not just the data collected from your users and the real world, but also the data generated by your model - its outputs and logs.
By looking at the individual outputs, you get a sense of how good (or bad) the model works. You can use the intuition you gained to add more specific details to your prompts.
For my HTR task, I noticed that with the previous prompts, gpt-4o-mini added an introductory response, such as:
Sure! Here is the transcription of the handwritten text:
---The model also often appended an ending response, such as:
---
Let me know if you need anything else!I did not want these unnecessary additions (including the section separators '---'). Moreover, gpt-4o-mini transcribed the page number on the top left corner of each journal page and the day and date on the top right corner. My ground-truth transcriptions omitted these details, so I also added specifications in my prompt to match the ground-truth data:
prompt = """You are the world's greatest transcriber
of handwritten notes. Transcribe the text from this
image accurately.
Do not add any other words nor section separators
in your response. Do not add in your output the page
number found on the top left corner of the image and
the day and date on the top right corner."""By adding details on my desired format in the prompt, gpt-4o-mini did not already add any filler words and it omitted the page numbers and dates in its outputs. The average CER and WER decreased to 15.2% and 21.0%, respectively. By looking at the data, we have improved the model's performance, with only one incorrect word for every five words it transcribed on the average.
Overall, our sequence of prompting tactics has steadily decreased gpt-4o-mini's error rates on both the character and word levels. Our final prompt is effective as it specified the persona, task, context, and format for our model. These are the four key areas highlighted in Google Gemini's Prompting Guide 101 Handbook.
A Closer Look at Variances#
Another story unfolds once we take a closer look at the variances of the error rates. Visualized below are the box and whisker plots of CER and WER for each prompt:
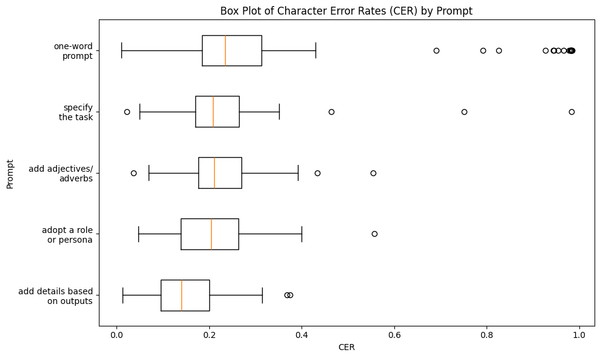
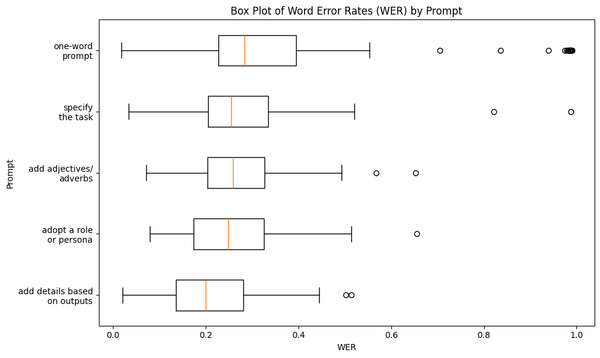
For the one-word prompt, the error rates were very drastic, going as high as 99.0% and as low as 1.7%. In fact these two figures are the most extreme values across all the error rates generated by the five prompts.
We can also observe that the lengths of the whiskers shorten as we apply our sequence of prompting tactics. Quantitatively, the standard deviations of the word error rates plummeted from 27.4% with the one-word prompt to 10.3% using our final prompt. This implies that applying consecutively our five prompting tactics has narrowed the focus of our model and made it more consistent in generating its responses.
Another interesting phenomenon from the box plots is the set of outliers. Throughout the sequence of prompts, there has been a consistent outlier with a very high error rate. It's my journal note last June 4, 2024 which is my longest entry to date. In my last blog post, I've shown that the length of journal note affects the model's error rate, and this finding still holds true even if we use varying prompts.
On the other end of the spectrum, my journal note for June 23, 2024 had very low error rate across all prompt iterations, consistently placing among the top three best-transcribed entries. Coincidentally, this entry was when I deliberately started to fix my handwriting for LLM ingestion.
🖊️ A Tip: Use gel pens over ballpens#
There was a week in the month of June when I wrote my journal entries using a ballpoint pen over my usual gel pen. My investigation with the set of outliers from the box plots above led me to a new discovery: the seven entries where I used a ballpen were consistently among the top journal notes that had the highest word error rates.
I speculated in my previous blog post that the type of writing tool I use is a factor contributing to error rates. My hypothesis seems to hold true. After visually examining my journal entries, I now see how my ballpoint pen produced thinner, more inconsistent lines as opposed to my gel pen. This may have contributed to the higher error rates when I used my ballpen, as it's more challenging for the model to transcribe thinner, illegible text.
This discovery forces me to visit my local bookstore more frequently so I can stock up on gel pens and not resort to using ballpens. Data quality matters - I have to do things within my control to increase the quality of my raw data 😆.
Conclusion#
While there have been polarizing discourses online on how overhyped prompt engineering is, I believe that learning how to phrase the problem you'd like an LLM to solve is still important. It's even beneficial to squeezing performance gains from the model, as evident in our experiments. Applying our sequence of prompting tactics to our HTR task iteratively produced lower and more consistent error rates. And we've got a bonus too: my exploration on writing effective prompts led to an assessment of my writing tools 🖊️😅.